
A voice-enabled smart speaker sits on a bedside table in a care home, with a resident in the background, surrounded by medication and care equipment,📷 Photo by Tech&Space
- ★330 spoken transcripts tested across 11 care categories
- ★Whisper + RAG combo faces real-world deployment gaps
- ★Admin workload claims meet safety evaluation reality
A voice-enabled smart speaker for care homes just got the kind of evaluation most consumer AI gadgets avoid: 330 spoken transcripts, 11 care categories, and a safety framework that treats "reminder-containing interactions" as potential failure points. The system—built on Whisper speech recognition and retrieval-augmented generation (RAG)—wasn’t just benchmarked in a lab but tested in supervised care-home trials, where the gap between demo fluency and real-world reliability becomes painfully obvious.
The paper’s core tension isn’t whether AI can transcribe care home tasks (it can) but whether it can do so safely—a question most AI health startups prefer to answer with pilot programs and press releases. Here, the evaluation framework explicitly examines end-to-end risks, from misheard medication reminders to scheduling conflicts that could cascade into staffing crises. That’s a refreshingly unsexy focus in a field where "reducing administrative workload" often serves as code for "we haven’t stress-tested this yet."
What’s actually new? The hybrid RAG approach (sparse + dense retrieval) isn’t novel, but applying it to care home workflows with a safety-first lens is. The 184 reminder-containing interactions in the test set suggest the team at least tried to simulate real-world chaos—unlike, say, the AI scribe tools flooding the market with claims of "seamless" documentation.
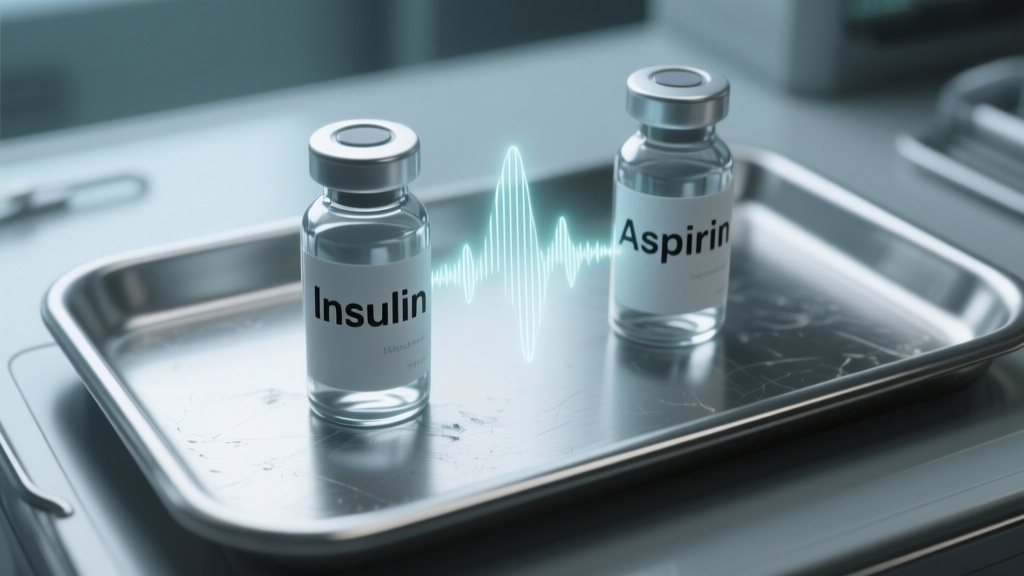
Between the benchmark and the bedside📷 Photo by Tech&Space
Between the benchmark and the bedside
The real signal here isn’t the tech stack—it’s the evaluation framework. By treating the system as a socio-technical risk rather than a pure NLP challenge, the researchers expose where most AI-in-healthcare projects stumble: the hand-off between algorithm and human. A speaker that mishears "insulin at 8 AM" as "aspirin at 8 PM" isn’t just a transcription error—it’s a patient safety incident waiting to happen. That the team tested this in controlled care-home trials (not just synthetic benchmarks) is the closest thing to a stress test this space has seen.
Industry-wise, this puts pressure on two fronts. First, the consumer smart speaker giants (Amazon, Google) now face a credibility gap: their health-focused skills and routines were never designed for high-stakes environments. Second, it gives regulators a template for what "safe" AI deployment in care settings might actually look like—something beyond "FDA-cleared for wellness use."
The developer community’s reaction? Muted but telling. While the arXiv paper got its usual upvotes, the comments focused less on the tech and more on the deployment challenges: staff training overhead, liability when errors occur, and the inevitable vendor lock-in if care homes standardize on one system. That’s the sound of engineers recognizing that the hard part isn’t the model—it’s the messy human context around it.